Experiment 4 - Multiple-step environments performance
Contents
import pathlib
import warnings
from collections import defaultdict
from itertools import groupby
import gym
import gym_corridor # noqa: F401
import gym_grid # noqa: F401
from IPython.display import HTML
from lcs import Perception
from myst_nb import glue
from tabulate import tabulate
from src.bayes_estimation import bayes_estimate
from src.bayes_plotting import plot_bayes_comparison
from src.commons import NUM_EXPERIMENTS
from src.decorators import repeat, get_from_cache_or_run
from src.discretized_experiments import *
from src.observation_wrappers import CorridorObservationWrapper
from src.utils import build_plots_dir_path, build_cache_dir_path
plt.ioff() # turn off interactive plotting
plt.style.use('../../../../src/phd.mplstyle')
root_dir = pathlib.Path().cwd().parent.parent.parent.parent
cwd_dir = pathlib.Path().cwd()
plot_dir = build_plots_dir_path(root_dir) / cwd_dir.parent.name / cwd_dir.name
cache_dir = build_cache_dir_path(root_dir) / cwd_dir.parent.name / cwd_dir.name
def generalization_score(pop):
# Compute proportion of wildcards in classifier condition across all classifiers
wildcards = sum(1 for cl in pop for cond in cl.condition if cond == '#' or (hasattr(cond, 'symbol') and cond.symbol == '#'))
all_symbols = sum(len(cl.condition) for cl in pop)
return wildcards / all_symbols
TRIALS = 300
USE_RAY = True
glue('33_e4_trials', TRIALS, display=False)
Experiment 4 - Multiple-step environments performance¶
The multistep learning performance was also examined by a set of five algorithms - ACS, ACS2, ACS2 with GA, YACS and Dyna-Q using the same metrics as in the single-step experiment case.
On the contrary, the problems investigated herein does not provide immediate feedback to the agent about the potential outcomes of the selected action. Therefore, a chain of correct decisions needs to be formed to locate the incentive. The Corridor is a one-dimensional grid discretized into 20 states, and Grid provides an extension by adding another dimension of the same length alongside two more possible actions.
In each trial of the experiment, the agent executes the exploration phase for the total of 300 trials solely. Moreover, to present coherent results and draw statistical inferences, each experiment is repeated 50 times.
corridor = gym.make('corridor-20-v0')
def corridor_knowledge(pop, env):
transitions = env.env.get_transitions()
reliable = [c for c in pop if c.is_reliable()]
nr_correct = 0
for start, action, end in transitions:
p0 = Perception((str(start),))
p1 = Perception((str(end),))
if any([True for cl in reliable if cl.predicts_successfully(p0, action, p1)]):
nr_correct += 1
return nr_correct / len(transitions)
def corridor_metrics_collect(agent, env):
population = agent.population
return {
'pop': len(population),
'knowledge': corridor_knowledge(population, env),
'generalization': generalization_score(population)
}
# DynaQ helpers
def dynaq_corridor_knowledge_calculator(model, env):
transitions = env.env.get_transitions()
nr_correct = 0
for (s0, a, s1) in transitions:
if s0 in model and a in model[s0] and model[s0][a][0] == s1:
nr_correct += 1
return nr_correct / len(transitions)
common_params = {
'classifier_length': 1,
'possible_actions': 2,
'learning_rate': 0.1,
'metrics_trial_freq': 1,
'metrics_fcn': corridor_metrics_collect,
'trials': TRIALS
}
yacs_params = {
'trace_length': 3,
'estimate_expected_improvements': False,
'feature_possible_values': [set(str(i) for i in range(19)), ]
}
dynaq_params = {
'q_init': np.zeros((corridor.env.observation_space.n, 2)),
'model_init': {},
'perception_to_state_mapper': lambda p: int(p),
'knowledge_fcn': dynaq_corridor_knowledge_calculator,
'epsilon': 0.5
}
class CorridorStateWrapper(gym.ObservationWrapper):
def observation(self, obs):
assert len(obs) == 1
return int(obs[0])
@get_from_cache_or_run(cache_path=f'{cache_dir}/corridor/acs.dill')
@repeat(num_times=NUM_EXPERIMENTS, use_ray=USE_RAY)
def run_corridor_with_acs():
return single_acs_experiment(
env_provider=lambda: CorridorObservationWrapper(corridor),
trials=common_params['trials'],
classifier_length=common_params['classifier_length'],
possible_actions=common_params['possible_actions'],
learning_rate=common_params['learning_rate'],
metrics_trial_freq=common_params['metrics_trial_freq'],
metrics_fcn=common_params['metrics_fcn'])
@get_from_cache_or_run(cache_path=f'{cache_dir}/corridor/acs2.dill')
@repeat(num_times=NUM_EXPERIMENTS, use_ray=USE_RAY)
def run_corridor_with_acs2():
return single_acs2_experiment(
env_provider=lambda: CorridorObservationWrapper(corridor),
trials=common_params['trials'],
classifier_length=common_params['classifier_length'],
possible_actions=common_params['possible_actions'],
learning_rate=common_params['learning_rate'],
do_ga=False,
initial_q=0.5,
metrics_trial_freq=common_params['metrics_trial_freq'],
metrics_fcn=common_params['metrics_fcn']
)
@get_from_cache_or_run(cache_path=f'{cache_dir}/corridor/acs2_ga.dill')
@repeat(num_times=NUM_EXPERIMENTS, use_ray=USE_RAY)
def run_corridor_with_acs2_ga():
return single_acs2_experiment(
env_provider=lambda: CorridorObservationWrapper(corridor),
trials=common_params['trials'],
classifier_length=common_params['classifier_length'],
possible_actions=common_params['possible_actions'],
learning_rate=common_params['learning_rate'],
do_ga=True,
initial_q=0.5,
metrics_trial_freq=common_params['metrics_trial_freq'],
metrics_fcn=common_params['metrics_fcn']
)
@get_from_cache_or_run(cache_path=f'{cache_dir}/corridor/yacs.dill')
@repeat(num_times=NUM_EXPERIMENTS, use_ray=USE_RAY)
def run_corridor_with_yacs():
return single_yacs_experiment(
env_provider=lambda: CorridorObservationWrapper(corridor),
trials=common_params['trials'],
classifier_length=common_params['classifier_length'],
possible_actions=common_params['possible_actions'],
learning_rate=common_params['learning_rate'],
trace_length=yacs_params['trace_length'],
estimate_expected_improvements=yacs_params['estimate_expected_improvements'],
feature_possible_values=yacs_params['feature_possible_values'],
metrics_trial_freq=common_params['metrics_trial_freq'],
metrics_fcn=common_params['metrics_fcn']
)
@get_from_cache_or_run(cache_path=f'{cache_dir}/corridor/dynaq.dill')
@repeat(num_times=NUM_EXPERIMENTS, use_ray=USE_RAY)
def run_corridor_with_dynaq():
return single_dynaq_experiment(
env_provider=lambda: CorridorStateWrapper(CorridorObservationWrapper(corridor)),
trials=common_params['trials'],
q_init=dynaq_params['q_init'],
model_init=dynaq_params['model_init'],
epsilon=dynaq_params['epsilon'],
learning_rate=common_params['learning_rate'],
knowledge_fcn=dynaq_params['knowledge_fcn'],
metrics_trial_freq=common_params['metrics_trial_freq']
)
# Run computations
corridor_acs_runs = run_corridor_with_acs()
corridor_acs2_runs = run_corridor_with_acs2()
corridor_acs2_ga_runs = run_corridor_with_acs2_ga()
corridor_yacs_runs = run_corridor_with_yacs()
corridor_dynaq_runs = run_corridor_with_dynaq()
# Collect metrics to single dataframe
corridor_metrics_df = pd.concat([
*[parse_lcs_metrics('acs', metrics) for _, metrics in corridor_acs_runs],
*[parse_lcs_metrics('acs2', metrics) for _, metrics in corridor_acs2_runs],
*[parse_lcs_metrics('acs2_ga', metrics) for _, metrics in corridor_acs2_ga_runs],
*[parse_lcs_metrics('yacs', metrics) for _, metrics in corridor_yacs_runs],
*[parse_dyna_metrics('dynaq', metrics) for _, _, metrics in corridor_dynaq_runs],
])
corridor_metrics_df.set_index(['agent', 'trial'], inplace=True)
# Average them by agent and trial
corridor_metrics_averaged_df = corridor_metrics_df.groupby(['agent', 'trial']).mean()
# Plot results
with warnings.catch_warnings():
warnings.simplefilter("ignore")
glue('corridor-performance-fig', plot_comparison(corridor_metrics_averaged_df, plot_filename=f'{plot_dir}/corridor_performance.png'), display=False)
def grid_env_provider():
import gym_grid # noqa: F401
grid = gym.make('grid-20-v0')
grid._max_episode_steps = 250
return grid
grid = grid_env_provider()
grid_transitions = grid.env._transitions
unique_states = set()
for (s0, a, s1) in grid_transitions:
unique_states.add(s0)
unique_states.add(s1)
grid_state_mapping = {idx: s for idx, s in enumerate(unique_states)}
# LCS helpers
def grid_knowledge(population, env):
transitions = env.env.get_transitions()
reliable = [c for c in population if c.is_reliable()]
nr_correct = 0
for start, action, end in transitions:
p0 = Perception([str(el) for el in start])
p1 = Perception([str(el) for el in end])
if any([True for cl in reliable if cl.predicts_successfully(p0, action, p1)]):
nr_correct += 1
return nr_correct / len(transitions)
def grid_metrics_collector(agent, env):
population = agent.population
return {
'pop': len(population),
'knowledge': grid_knowledge(population, env),
'generalization': generalization_score(population)
}
# DynaQ helpers
def grid_perception_to_int(p0):
p0m = tuple(map(int, p0))
return list(grid_state_mapping.keys())[list(grid_state_mapping.values()).index(p0m)]
class GridStateWrapper(gym.ObservationWrapper):
def observation(self, obs):
return grid_perception_to_int(obs)
def grid_dynaq_env_provider():
return GridStateWrapper(grid_env_provider())
def dynaq_grid_knowledge_calculator(model, env):
all_transitions = 0
nr_correct = 0
for p0, a, p1 in grid_transitions:
s0 = grid_perception_to_int(p0)
s1 = grid_perception_to_int(p1)
all_transitions += 1
if s0 in model and a in model[s0] and model[s0][a][0] == s1:
nr_correct += 1
return nr_correct / all_transitions
common_params = {
'classifier_length': 2,
'possible_actions': 4,
'learning_rate': 0.1,
'metrics_trial_freq': 1,
'metrics_fcn': grid_metrics_collector,
'trials': TRIALS
}
yacs_params = {
'trace_length': 3,
'estimate_expected_improvements': False,
'feature_possible_values': [
set(str(i) for i in range(20)),
set(str(i) for i in range(20))
]
}
dynaq_params = {
'q_init': np.zeros((len(grid_state_mapping), 4)),
'model_init': {},
'perception_to_state_mapper': grid_perception_to_int,
'knowledge_fcn': dynaq_grid_knowledge_calculator,
'epsilon': 0.5,
}
@get_from_cache_or_run(cache_path=f'{cache_dir}/grid/acs.dill')
@repeat(num_times=NUM_EXPERIMENTS, use_ray=USE_RAY)
def run_grid_with_acs():
return single_acs_experiment(
env_provider=grid_env_provider,
trials=common_params['trials'],
classifier_length=common_params['classifier_length'],
possible_actions=common_params['possible_actions'],
learning_rate=common_params['learning_rate'],
metrics_trial_freq=common_params['metrics_trial_freq'],
metrics_fcn=common_params['metrics_fcn'])
@get_from_cache_or_run(cache_path=f'{cache_dir}/grid/acs2.dill')
@repeat(num_times=NUM_EXPERIMENTS, use_ray=USE_RAY)
def run_grid_with_acs2():
return single_acs2_experiment(
env_provider=grid_env_provider,
trials=common_params['trials'],
classifier_length=common_params['classifier_length'],
possible_actions=common_params['possible_actions'],
learning_rate=common_params['learning_rate'],
do_ga=False,
initial_q=0.5,
metrics_trial_freq=common_params['metrics_trial_freq'],
metrics_fcn=common_params['metrics_fcn']
)
@get_from_cache_or_run(cache_path=f'{cache_dir}/grid/acs2_ga.dill')
@repeat(num_times=NUM_EXPERIMENTS, use_ray=USE_RAY)
def run_grid_with_acs2_ga():
return single_acs2_experiment(
env_provider=grid_env_provider,
trials=common_params['trials'],
classifier_length=common_params['classifier_length'],
possible_actions=common_params['possible_actions'],
learning_rate=common_params['learning_rate'],
do_ga=True,
initial_q=0.5,
metrics_trial_freq=common_params['metrics_trial_freq'],
metrics_fcn=common_params['metrics_fcn']
)
@get_from_cache_or_run(cache_path=f'{cache_dir}/grid/yacs.dill')
@repeat(num_times=NUM_EXPERIMENTS, use_ray=USE_RAY)
def run_grid_with_yacs():
return single_yacs_experiment(
env_provider=grid_env_provider,
trials=common_params['trials'],
classifier_length=common_params['classifier_length'],
possible_actions=common_params['possible_actions'],
learning_rate=common_params['learning_rate'],
trace_length=yacs_params['trace_length'],
estimate_expected_improvements=yacs_params['estimate_expected_improvements'],
feature_possible_values=yacs_params['feature_possible_values'],
metrics_trial_freq=common_params['metrics_trial_freq'],
metrics_fcn=common_params['metrics_fcn']
)
@get_from_cache_or_run(cache_path=f'{cache_dir}/grid/dynaq.dill')
@repeat(num_times=NUM_EXPERIMENTS, use_ray=USE_RAY)
def run_grid_with_dynaq():
return single_dynaq_experiment(
env_provider=grid_dynaq_env_provider,
trials=common_params['trials'],
q_init=dynaq_params['q_init'],
model_init=dynaq_params['model_init'],
epsilon=dynaq_params['epsilon'],
learning_rate=common_params['learning_rate'],
knowledge_fcn=dynaq_params['knowledge_fcn'],
metrics_trial_freq=common_params['metrics_trial_freq']
)
# Run computations
grid_acs_runs = run_grid_with_acs()
grid_acs2_runs = run_grid_with_acs2()
grid_acs2_ga_runs = run_grid_with_acs2_ga()
grid_yacs_runs = run_grid_with_yacs()
grid_dynaq_runs = run_grid_with_dynaq()
# Collect metrics to single dataframe
grid_metrics_df = pd.concat([
*[parse_lcs_metrics('acs', metrics) for _, metrics in grid_acs_runs],
*[parse_lcs_metrics('acs2', metrics) for _, metrics in grid_acs2_runs],
*[parse_lcs_metrics('acs2_ga', metrics) for _, metrics in grid_acs2_ga_runs],
*[parse_lcs_metrics('yacs', metrics) for _, metrics in grid_yacs_runs],
*[parse_dyna_metrics('dynaq', metrics) for _, _, metrics in grid_dynaq_runs],
])
grid_metrics_df.set_index(['agent', 'trial'], inplace=True)
# Average them by agent and trial
grid_metrics_averaged_df = grid_metrics_df.groupby(['agent', 'trial']).mean()
# Plot results
with warnings.catch_warnings():
warnings.simplefilter("ignore")
glue('grid-performance-fig', plot_comparison(grid_metrics_averaged_df, plot_filename=f'{plot_dir}/grid-performance.png'), display=False)
Results¶
Common parameters that were used across the experiments included the following: learning rate \(\beta=0.1\), exploration probability \(\epsilon=0.5\), discount factor \(\gamma=0.95\), inadequacy threshold \(\theta_i=0.1\), reliability threshold \(\theta_r=0.9\), YACS trace length 3. The Dyna-Q algorithm performs five steps ahead simulation in each trial
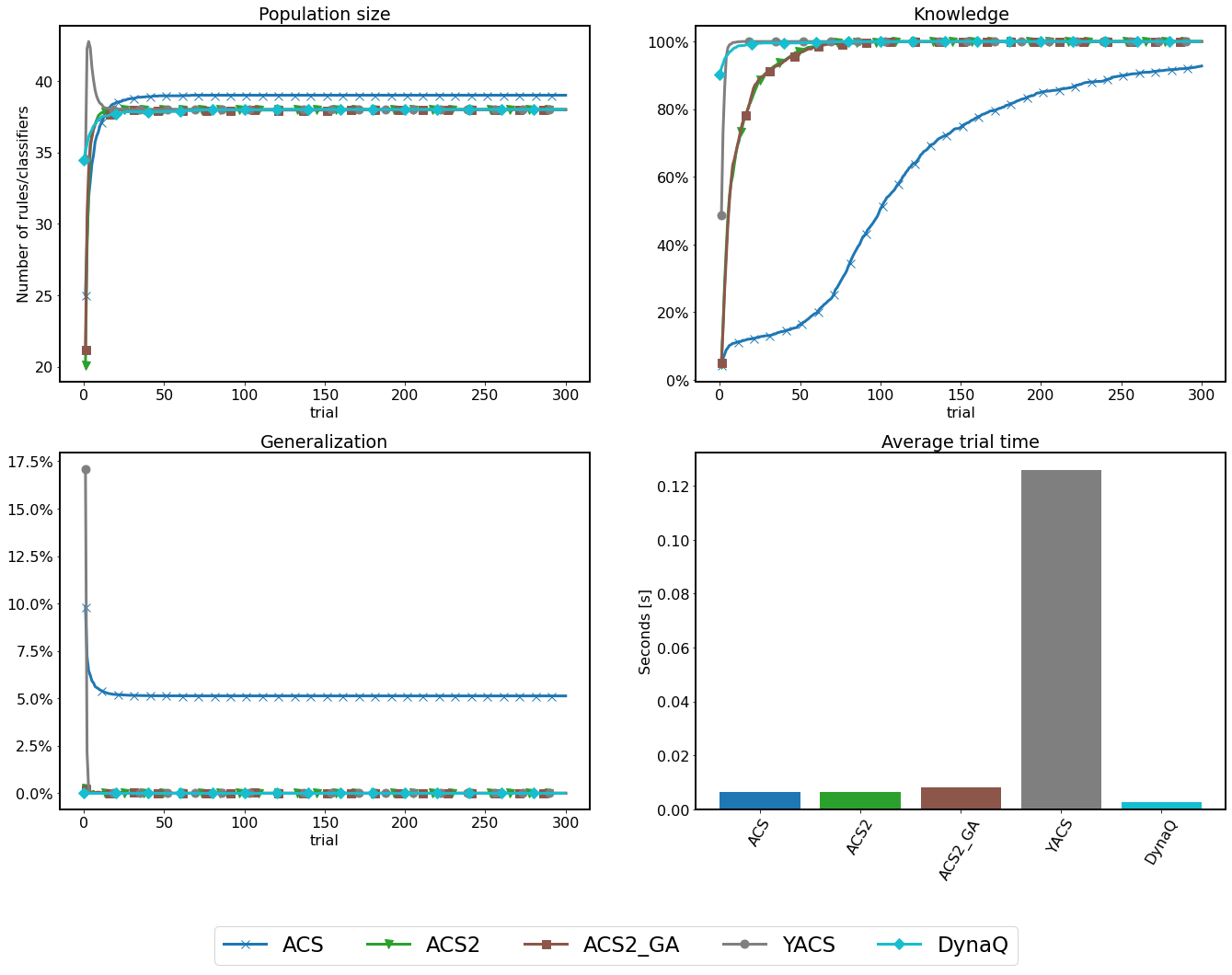
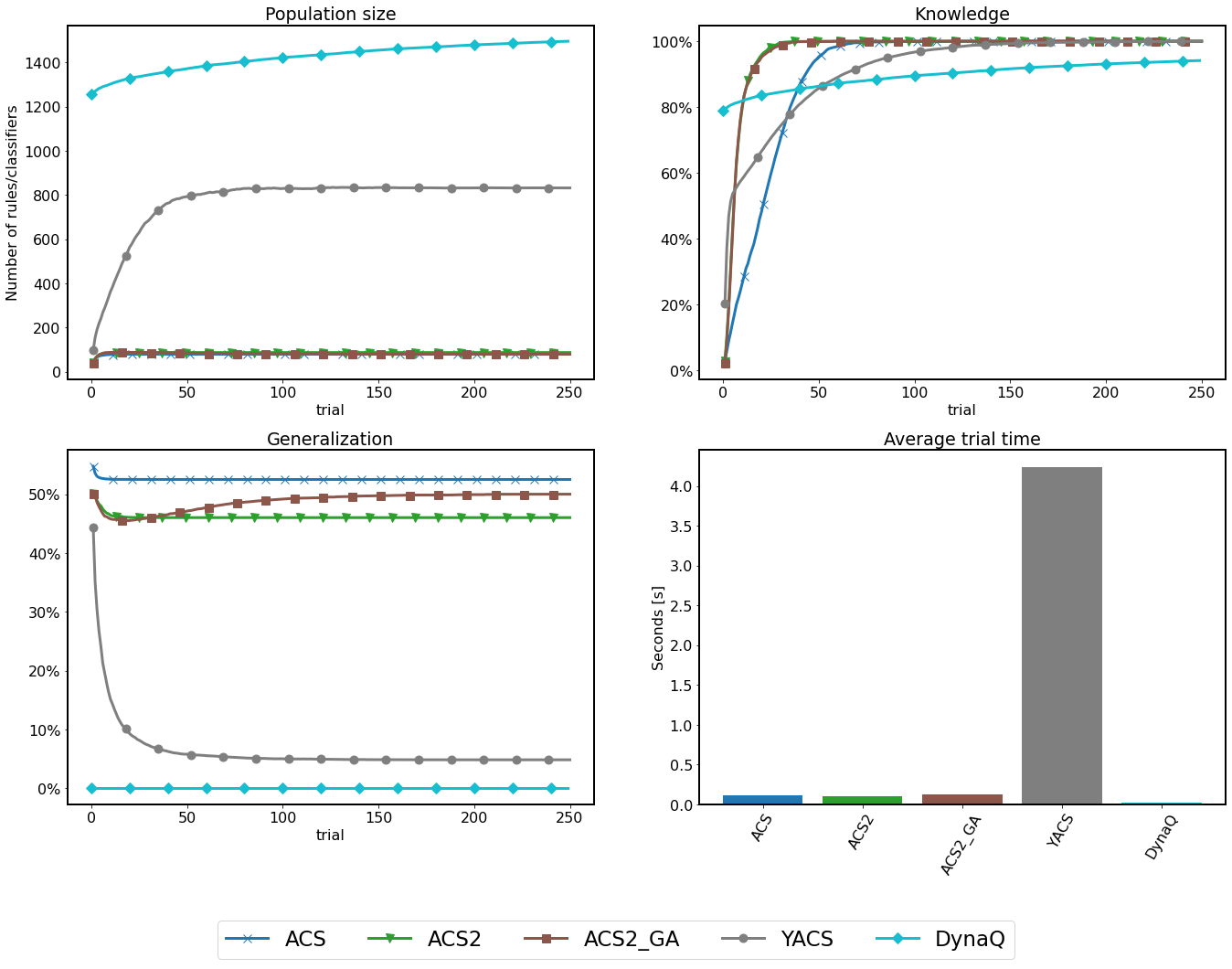
Statistical verification¶
The posterior data distribution was modelled using 50 metric values collected in the last trial and then sampled with 100,000 draws. Obtained results were presented in the table and using the radar plot scaled accordingly, highlighting the relative differences between algorithms.
agents = ['acs', 'acs2', 'acs2_ga', 'yacs', 'dynaq']
print_row = lambda r: f'{round(r.mean(), 3)} ± {round(r.std(), 3)}'
def build_models(df: pd.DataFrame, field: str):
results = {}
for agent in agents:
last_trial = df.reset_index(1).query(f'agent == "{agent}"')['trial'].max()
data_arr = df.query(f'agent == "{agent}" and trial == {last_trial}')[field].to_numpy()
bayes_model = bayes_estimate(data_arr)
results[agent] = bayes_model['mu']
return results
def build_bayes_data_structures(agents, knowledge_models, generalization_models, population_models, timing_models):
payload_df = []
table_data = []
for agent in agents:
# prepare data frame for visualization
payload_df.append({
'agent': agent,
'knowledge': knowledge_models[agent].mean(),
'generalization': generalization_models[agent].mean(),
'population': population_models[agent].mean(),
'time': timing_models[agent].mean()
})
# add data to table
table_data.append([agent.upper(),
print_row(knowledge_models[agent]),
print_row(generalization_models[agent]),
print_row(population_models[agent]),
print_row(timing_models[agent])])
bayes_df = pd.DataFrame(payload_df).set_index('agent')
bayes_table = tabulate(table_data,
headers=['', 'Knowledge', 'Generalization', 'Population', 'Trial time'],
tablefmt="html", stralign='right')
return HTML(bayes_table), bayes_df
# corridor
@get_from_cache_or_run(cache_path=f'{cache_dir}/corridor/bayes/population.dill')
def build_corridor_population_model():
return build_models(corridor_metrics_df, 'population')
@get_from_cache_or_run(cache_path=f'{cache_dir}/corridor/bayes/knowledge.dill')
def build_corridor_knowledge_models():
return build_models(corridor_metrics_df, 'knowledge')
@get_from_cache_or_run(cache_path=f'{cache_dir}/corridor/bayes/generalization.dill')
def build_corridor_generalization_models():
return build_models(corridor_metrics_df, 'generalization')
@get_from_cache_or_run(cache_path=f'{cache_dir}/corridor/bayes/timing.dill')
def build_corridor_timing_models():
return build_models(corridor_metrics_df, 'time')
# grid
@get_from_cache_or_run(cache_path=f'{cache_dir}/grid/bayes/population.dill')
def build_grid_population_model():
return build_models(grid_metrics_df, 'population')
@get_from_cache_or_run(cache_path=f'{cache_dir}/grid/bayes/knowledge.dill')
def build_grid_knowledge_models():
return build_models(grid_metrics_df, 'knowledge')
@get_from_cache_or_run(cache_path=f'{cache_dir}/grid/bayes/generalization.dill')
def build_grid_generalization_models():
return build_models(grid_metrics_df, 'generalization')
@get_from_cache_or_run(cache_path=f'{cache_dir}/grid/bayes/timing.dill')
def build_grid_timing_models():
return build_models(grid_metrics_df, 'time')
# BEST models
corridor_population_models = build_corridor_population_model()
corridor_knowledge_models = build_corridor_knowledge_models()
corridor_generalization_models = build_corridor_generalization_models()
corridor_timing_models = build_corridor_timing_models()
grid_population_models = build_grid_population_model()
grid_knowledge_models = build_grid_knowledge_models()
grid_generalization_models = build_grid_generalization_models()
grid_timing_models = build_grid_timing_models()
corridor_bayes_table, corridor_bayes_df = build_bayes_data_structures(agents, corridor_knowledge_models, corridor_generalization_models, corridor_population_models, corridor_timing_models)
grid_bayes_table, grid_bayes_df = build_bayes_data_structures(agents, grid_knowledge_models, grid_generalization_models, grid_population_models, grid_timing_models)
glue('ch33_2_corridor_bayes_table', corridor_bayes_table, display=False)
glue('ch33_2_grid_bayes_table', grid_bayes_table, display=False)
glue('ch33_2_corridor_bayes_fig', plot_bayes_comparison(corridor_bayes_df, 'Corridor', agents, plot_filename=f'{plot_dir}/corridor_bayes.png'), display=False)
glue('ch33_2_grid_bayes_fig', plot_bayes_comparison(grid_bayes_df, 'Grid', agents, plot_filename=f'{plot_dir}/grid_bayes.png'), display=False)
Corridor¶
Knowledge Generalization Population Trial time ACS 0.93 ± 0.009 0.051 ± 0.0 39.0 ± 0.0 0.007 ± 0.001 ACS2 1.0 ± 0.0 0.0 ± 0.0 38.0 ± 0.0 0.006 ± 0.001 ACS2_GA 1.0 ± 0.0 0.0 ± 0.0 38.0 ± 0.001 0.008 ± 0.001 YACS 1.0 ± 0.0 0.0 ± 0.0 38.0 ± 0.0 0.104 ± 0.012 DYNAQ 1.0 ± 0.0 0.0 ± 0.0 38.0 ± 0.0 0.002 ± 0.001
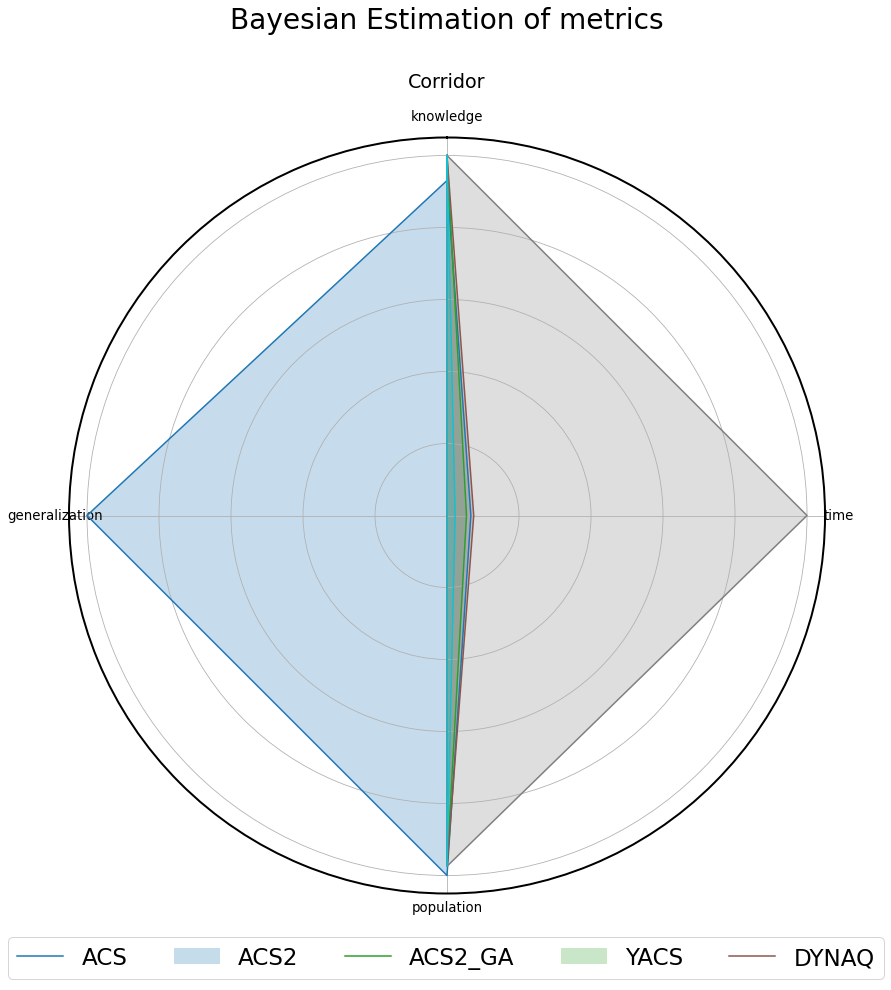
Fig. 3.14 Normalized metrics presented on the radar plot for Corridor-20 environment.¶
Grid¶
Knowledge Generalization Population Trial time ACS 1.0 ± 0.0 0.525 ± 0.0 80.0 ± 0.0 0.117 ± 0.002 ACS2 1.0 ± 0.0 0.461 ± 0.005 87.049 ± 0.954 0.115 ± 0.004 ACS2_GA 1.0 ± 0.0 0.5 ± 0.0 80.0 ± 0.0 0.126 ± 0.005 YACS 1.0 ± 0.001 0.022 ± 0.002 830.655 ± 50.379 4.299 ± 0.33 DYNAQ 0.978 ± 0.008 0.0 ± 0.0 1551.849 ± 16.427 0.025 ± 0.003
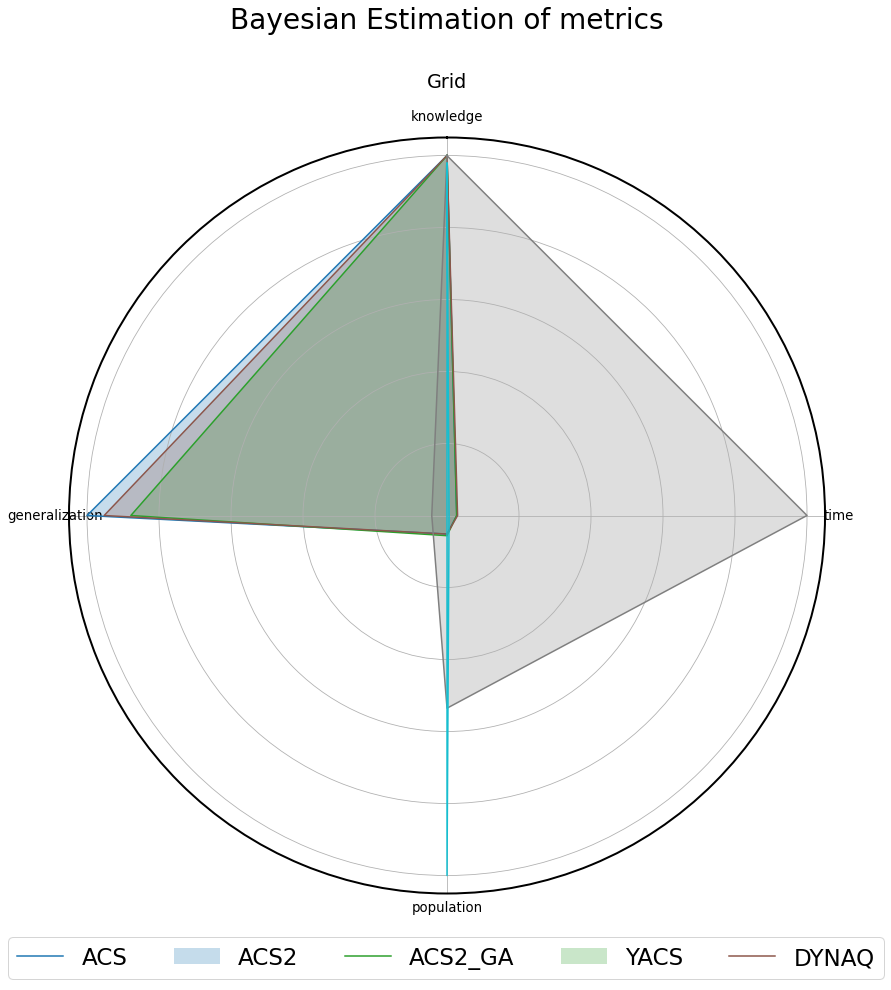
Fig. 3.15 Normalized metrics presented on the radar plot for Grid-20 environment.¶
@get_from_cache_or_run(cache_path=f'{cache_dir}/grid/comparison.dill')
def evaluate_simple_classifiers(trials=25):
acs_results = single_acs_experiment(
env_provider=grid_env_provider,
trials=trials,
classifier_length=common_params['classifier_length'],
possible_actions=common_params['possible_actions'],
learning_rate=common_params['learning_rate'],
metrics_trial_freq=common_params['metrics_trial_freq'],
metrics_fcn=common_params['metrics_fcn'])
acs2_results = single_acs2_experiment(
env_provider=grid_env_provider,
trials=trials,
classifier_length=common_params['classifier_length'],
possible_actions=common_params['possible_actions'],
learning_rate=common_params['learning_rate'],
do_ga=False,
initial_q=0.5,
metrics_trial_freq=common_params['metrics_trial_freq'],
metrics_fcn=common_params['metrics_fcn']
)
yacs_results = single_yacs_experiment(
env_provider=grid_env_provider,
trials=trials,
classifier_length=common_params['classifier_length'],
possible_actions=common_params['possible_actions'],
learning_rate=common_params['learning_rate'],
trace_length=yacs_params['trace_length'],
estimate_expected_improvements=yacs_params['estimate_expected_improvements'],
feature_possible_values=yacs_params['feature_possible_values'],
metrics_trial_freq=common_params['metrics_trial_freq'],
metrics_fcn=common_params['metrics_fcn']
)
return acs_results[0].population, acs2_results[0].population, yacs_results[0].population
def build_classifier_comparison_df(perception):
def print_cl(cl):
moves = ['←', '→', '↑', '↓']
return f"{cl.condition} {moves[cl.action]} {cl.effect}"
results = defaultdict(list)
for agent, population in zip(['ACS', 'ACS2', 'YACS'], [acs_grid_pop, acs2_grid_pop, yacs_grid_pop]):
sorted_match_set = sorted(population.form_match_set(perception), key=lambda cl: cl.action)
for action, cls in groupby(sorted_match_set, key=lambda cl: cl.action):
results[agent].append(', '.join([print_cl(cl) for cl in cls]))
return pd.DataFrame(results)
acs_grid_pop, acs2_grid_pop, yacs_grid_pop = evaluate_simple_classifiers()
perception = Perception(('18', '19'))
glue('grid_cls_comparison_df', build_classifier_comparison_df(perception), display=False)
Observations¶
All investigated algorithms converge towards obtaining complete knowledge of selected problems. Interesting behavioural patterns are revealed despite the relatively small number of input-space.
ACS
For the simple Corridor environment, the ACS maintains a stable population with only one irrelevant classifier, therefore wrongly suggesting generalization capabilities. The agent has the slowest learning rate.
Surprisingly, the Grid environment managed to have the smallest population of classifiers with the highest generalization score outperforming other agents.
ACS2
Since the lack of generalization capabilities in the Corridor problem, the performance of ACS2 and ACS2 GA is identical in this environment. They modelled the environment internally using a minimal possible number of rules. In the Grid environment, the GA addition further reduced the population size by extending the applicability of rules covering greater environmental niches.
YACS
The YACS, on average, took the longest amount of time to compute each trial. The Corridor case started very rapidly by generating an overpopulation of classifiers (being the fastest of learning the whole environment) and eventually settled into optimal values. However, it could not form the correct population size for the Grid problem. While knowing the consequences of all actions, the under-performing generalization resulted in an excessive number of classifiers.
The visual comparison of rules created for certain environmental perception in the Grid environment is shown in Fig. 3.16.
| ACS | ACS2 | YACS | |
|---|---|---|---|
| 0 | ## ← ##, 18# ← 17# | 18# ← 17# | 18# ← 17# |
| 1 | ## → ##, 18# → 19# | 18# → 19# | 1819 → ##, 1819 → 19# |
| 2 | ## ↑ ## | #19 ↑ ## | #19 ↑ ## |
| 3 | ## ↓ ##, #19 ↓ #18 | #19 ↓ #18 | 18# ↓ #5, 18# ↓ #4 |
Fig. 3.16 Classifier structure comparison in Grid environment for the \((18,19)\) state. The population was created after 25 explore trials. For each action, ACS2 manages to create a correct list of classifiers. The ACS is slower, and an initial default classifier accompanies each action. Finally, the YACS is unable to create fully general and accurate classifiers at all¶
Dyna-Q
Dyna-Q stands out in computation time, being the fastest investigated algorithm. However, complete representation of all possible state-action transitions needs to explicitly process each environmental interaction, which might be difficult with potential noise or other disturbances. Therefore, the knowledge accumulation process was significantly slower compared to other algorithms.
Software packages used
import session_info
session_info.show()
Click to view session information
----- gym 0.21.0 gym_corridor NA gym_grid NA lcs NA matplotlib 3.5.1 myst_nb 0.13.1 numpy 1.22.1 pandas 1.4.0 session_info 1.0.0 src (embedded book's utils module) tabulate 0.8.9 -----
Click to view modules imported as dependencies
PIL 8.4.0 arviz 0.11.2 asttokens NA attr 21.4.0 babel 2.9.1 backcall 0.2.0 beta_ufunc NA binom_ufunc NA brotli NA cachetools 5.0.0 certifi 2021.10.08 cffi 1.15.0 cftime 1.5.2 charset_normalizer 2.0.10 click 7.1.2 cloudpickle 2.0.0 colorama 0.4.4 colorful 0.5.4 colorful_orig 0.5.4 cryptography 36.0.1 cycler 0.10.0 cython_runtime NA databricks_cli NA dateutil 2.8.2 debugpy 1.5.1 decorator 5.1.1 defusedxml 0.7.1 dill 0.3.4 docutils 0.16 entrypoints 0.3 executing 0.8.2 fastprogress 0.2.7 filelock 3.4.2 google NA greenlet 1.1.2 grpc 1.43.0 hiredis 2.0.0 idna 3.3 imagesize NA importlib_metadata NA ipykernel 6.7.0 ipython_genutils 0.2.0 ipywidgets 7.6.5 jedi 0.18.1 jinja2 3.0.3 jsonschema 3.2.0 jupyter_cache 0.4.3 jupyter_sphinx 0.3.2 jupyterlab_pygments 0.1.2 kiwisolver 1.3.2 linkify_it 1.0.3 markdown_it 1.1.0 markupsafe 2.0.1 matplotlib_inline NA mdit_py_plugins 0.2.8 mistune 0.8.4 mlflow 1.23.1 mpl_toolkits NA msgpack 1.0.3 myst_parser 0.15.2 nbclient 0.5.10 nbconvert 6.4.1 nbformat 5.1.3 nbinom_ufunc NA netCDF4 1.5.8 packaging 21.3 pandocfilters NA parso 0.8.3 pexpect 4.8.0 pickleshare 0.7.5 pkg_resources NA prompt_toolkit 3.0.26 psutil 5.9.0 ptyprocess 0.7.0 pure_eval 0.2.2 pvectorc NA pydev_ipython NA pydevconsole NA pydevd 2.6.0 pydevd_concurrency_analyser NA pydevd_file_utils NA pydevd_plugins NA pydevd_tracing NA pygments 2.11.2 pylab NA pymc3 3.11.4 pyparsing 3.0.7 pyrsistent NA pytz 2021.3 ray 1.9.2 redis 4.1.2 requests 2.27.1 scipy 1.7.3 semver 2.13.0 setproctitle 1.2.2 setuptools 60.5.0 six 1.16.0 socks 1.7.1 sphinx 4.4.0 sphinxcontrib NA sqlalchemy 1.4.31 stack_data 0.1.4 testpath 0.5.0 theano 1.1.2 tornado 6.1 tqdm 4.62.3 traitlets 5.1.1 typing_extensions NA uc_micro 1.0.1 unicodedata2 NA urllib3 1.26.8 wcwidth 0.2.5 xarray 0.21.0 yaml 6.0 zipp NA zmq 22.3.0
----- IPython 8.0.1 jupyter_client 7.1.2 jupyter_core 4.9.1 notebook 6.4.8 ----- Python 3.9.10 | packaged by conda-forge | (main, Feb 1 2022, 21:24:11) [GCC 9.4.0] Linux-5.13.0-30-generic-x86_64-with-glibc2.31 ----- Session information updated at 2022-02-24 12:35