Experiment 1 - Single-step problem performance
Contents
import pathlib
from typing import List, Dict
import gym
import matplotlib.pyplot as plt
import matplotlib.ticker as mtick
import pandas as pd
from IPython.display import HTML
from lcs.agents.acs2 import Configuration, ACS2
from lcs.metrics import population_metrics
from lcs.strategies.action_selection import EpsilonGreedy, ActionDelay, KnowledgeArray
from myst_nb import glue
from tabulate import tabulate
from src.bayes_estimation import bayes_estimate
from src.commons import NUM_EXPERIMENTS
from src.decorators import repeat, get_from_cache_or_run
from src.utils import build_plots_dir_path, build_cache_dir_path
from src.visualization import biased_exploration_colors, PLOT_DPI
COLORS = biased_exploration_colors()
plt.ioff() # turn off interactive plotting
root_dir = pathlib.Path().cwd().parent.parent.parent
cwd_dir = pathlib.Path().cwd()
plot_dir = build_plots_dir_path(root_dir) / cwd_dir.name
cache_dir = build_cache_dir_path(root_dir) / cwd_dir.name
def run_alternating_experiment(env_provider, trials, **conf):
env = env_provider()
env.reset()
cfg = Configuration(**conf)
agent = ACS2(cfg)
metrics = agent.explore_exploit(env, trials)
# parse metrics
lst = [[d['trial'], d['reward'], d['population'], d['reliable']] for d in metrics]
df = pd.DataFrame(lst, columns=['trial', 'reward', 'population', 'reliable'])
# df = df.set_index('trial')
df['phase'] = df.index.map(lambda t: "exploit" if t % 2 == 0 else "explore")
return df
def average_experiment_runs(runs_dfs: List[pd.DataFrame]) -> pd.DataFrame:
return pd.concat(runs_dfs).groupby(['trial', 'phase']).mean().reset_index(level='phase')
def plot_rmpx(epsilon_greedy_df, action_delay_df, knowledge_array_df, op_initial_df, env_name, bins, plot_filename=None):
def plot_by_phase(df, window, label, color, ax):
# manually renamed phases due to the bug in cached results
explore_df = df[df['phase'] == 'exploit']
exploit_df = df[df['phase'] == 'explore']
explore_df.reset_index(inplace=True)
exploit_df.reset_index(inplace=True)
explore_df['reward'].rolling(window=window).mean().plot(label=label, color=color, ls='--', alpha=0.2, ax=ax)
exploit_df['reward'].rolling(window=window).mean().plot(label=label, color=color, ax=ax)
fig = plt.figure(figsize=(14, 10))
# Plots layout
gs = fig.add_gridspec(2, 1, hspace=.8)
ax1 = fig.add_subplot(gs[0])
ax2 = fig.add_subplot(gs[1])
# Global title
fig.suptitle(f'Performance of [{env_name}] environment discretized with {bins} bins', fontsize=24)
# Each axis
ma_window = 500 # moving average window
# Average reward
plot_by_phase(epsilon_greedy_df, ma_window, 'Epsilon Greedy', COLORS['eg'], ax1)
plot_by_phase(action_delay_df, ma_window, 'Action Delay', COLORS['ad'], ax1)
plot_by_phase(knowledge_array_df, ma_window, 'Knowledge Array', COLORS['ka'], ax1)
plot_by_phase(op_initial_df, ma_window, 'Optimistic Initial Quality', COLORS['oiq'], ax1)
ax1.spines['top'].set_visible(False)
ax1.spines['right'].set_visible(False)
ax1.set_title('Average Reward')
ax1.set_xlabel('Trial')
ax1.set_ylabel('Reward')
ax1.set_ylim(300, 1050)
ax1.axhline(y=1000, color='black', linewidth=1, linestyle="--")
# Population
epsilon_greedy_df['reliable'].rolling(window=ma_window).mean().plot(label='Epsilon Greedy', c=COLORS['eg'], ax=ax2)
action_delay_df['reliable'].rolling(window=ma_window).mean().plot(label='Action Delay', c=COLORS['ad'], ax=ax2)
knowledge_array_df['reliable'].rolling(window=ma_window).mean().plot(label='Knowledge Array', c=COLORS['ka'], ax=ax2)
op_initial_df['reliable'].rolling(window=ma_window).mean().plot(label='Optimistic Initial Quality', c=COLORS['oiq'], ax=ax2)
ax2.spines['top'].set_visible(False)
ax2.spines['right'].set_visible(False)
ax2.set_xlabel('Trial')
ax2.set_ylabel('Classifiers count')
ax2.set_title('Reliable Classifiers')
ax2.xaxis.set_major_formatter(mtick.FormatStrFormatter('%.0f'))
ax2.yaxis.set_major_formatter(mtick.FormatStrFormatter('%.0f'))
# Create legend
handles, labels = ax2.get_legend_handles_labels()
fig.legend(handles, labels, loc='lower center', ncol=4)
# Save plot to file
if plot_filename:
fig.savefig(plot_filename, dpi=PLOT_DPI)
return fig
# settings
USE_RAY = True
rmpx_bits = 6 # available sizes: 3, 6
rmpx_trials = 2 * 15_000 # explore-exploit-explore-...
bins_v1, bins_v2, bins_v3 = 5, 6, 7
glue('41_e1_trials', rmpx_trials, display=False)
glue('41_e1_encoding_bits', rmpx_bits, display=False)
Experiment 1 - Single-step problem performance¶
The effect of biasing exploration was first evaluated on the single-step 6-bit Real Multiplexer environment. The input was discretized using the following buckets of sizes alongside the respective size of the input space:
5 bits - \(2\cdot 5^6=31250\) possible states,
6 bits - \(2\cdot 6^6=93312\) possible states,
7 bits - \(2\cdot 7^6=235298\) possible states.
Each experiment was performed by alternating explore and exploit phases for 30000 trials. The cross-over capabilities were deliberately disabled because the last bit in perception \(\sigma\) was denoting the prediction result, which might inadvertently cause invalid rule evolution.
The efficiency of aforementioned biased exploration strategies is measured by studying the trajectory of the average reward and classifiers population size plots over time. Figures 4.1, 4.2 and 4.3 presents the average aggregation of results along with statistical inference calculated over 50 independent runs.
Results¶
ACS2 parameters
\(\beta=0.2\), \(\gamma = 0.95\), \(\theta_r = 0.9\), \(\theta_i=0.1\), \(\epsilon = 0.8\) \(\theta_{GA} = 50\), \(\theta_{AS}=20\), \(\theta_{exp}=50\), \(m_u=0.03\), \(u_{max}=4\), \(\chi=0.0\)
from src.observation_wrappers import BinnedObservationWrapper
def rmpx_metrics(agent, env):
pop = agent.population
metrics = {
'reliable': len([cl for cl in pop if cl.is_reliable()])
}
metrics.update(population_metrics(pop, env))
return metrics
def rmpx_env_provider(bins):
import gym_multiplexer # noqa: F401
return BinnedObservationWrapper(gym.make(f'real-multiplexer-{rmpx_bits}bit-v0'), bins)
rmpx_base_params = {
"classifier_length": rmpx_bits + 1,
"number_of_possible_actions": 2,
"epsilon": 0.8,
"beta": 0.2,
"gamma": 0.95,
"initial_q": 0.5,
"theta_exp": 50,
"theta_ga": 50,
"do_ga": True,
"chi": 0.0,
"mu": 0.03,
"u_max": 4,
"metrics_trial_frequency": 1,
"user_metrics_collector_fcn": rmpx_metrics
}
# Start experiments
def run_rmpx_biased_exploration(bins):
env_provider = lambda: rmpx_env_provider(bins)
eg = run_alternating_experiment(env_provider, rmpx_trials, **(rmpx_base_params | {'action_selector': EpsilonGreedy}))
ad = run_alternating_experiment(env_provider, rmpx_trials, **(rmpx_base_params | {'action_selector': ActionDelay, 'biased_exploration_prob': 0.5}))
ka = run_alternating_experiment(env_provider, rmpx_trials, **(rmpx_base_params | {'action_selector': KnowledgeArray, 'biased_exploration_prob': 0.5}))
oiq = run_alternating_experiment(env_provider, rmpx_trials, **(rmpx_base_params | {'action_selector': EpsilonGreedy, 'biased_exploration_prob': 0.8}))
return eg, ad, ka, oiq
@get_from_cache_or_run(cache_path=f'{cache_dir}/rmpx/bins_{bins_v1}.dill')
@repeat(num_times=NUM_EXPERIMENTS, use_ray=USE_RAY)
def rmpx_bins_v1():
return run_rmpx_biased_exploration(bins_v1)
@get_from_cache_or_run(cache_path=f'{cache_dir}/rmpx/bins_{bins_v2}.dill')
@repeat(num_times=NUM_EXPERIMENTS, use_ray=USE_RAY)
def rmpx_bins_v2():
return run_rmpx_biased_exploration(bins_v2)
@get_from_cache_or_run(cache_path=f'{cache_dir}/rmpx/bins_{bins_v3}.dill')
@repeat(num_times=NUM_EXPERIMENTS, use_ray=USE_RAY)
def rmpx_bins_v3():
return run_rmpx_biased_exploration(bins_v3)
def extract(experiment_runs):
eg_dfs, ad_dfs, ka_dfs, oiq_dfs = [], [], [], []
for eg_df, ad_df, ka_df, oiq_df in experiment_runs:
eg_dfs.append(eg_df)
ad_dfs.append(ad_df)
ka_dfs.append(ka_df)
oiq_dfs.append(oiq_df)
return eg_dfs, ad_dfs, ka_dfs, oiq_dfs
# Run calculations
for bins, run_output in zip(
[bins_v1, bins_v2, bins_v3],
[rmpx_bins_v1(), rmpx_bins_v2(), rmpx_bins_v3()]):
eg_dfs, ad_dfs, ka_dfs, oiq_dfs = extract(run_output)
plot_fig = plot_rmpx(
average_experiment_runs(eg_dfs),
average_experiment_runs(ad_dfs),
average_experiment_runs(ka_dfs),
average_experiment_runs(oiq_dfs),
env_name=rmpx_env_provider(bins).unwrapped.spec.id,
bins=bins,
plot_filename=f'{plot_dir}/rmpx-{bins}-bins-performance.png'
)
glue(f'rmpx_{bins}_bins_fig', plot_fig, display=False)
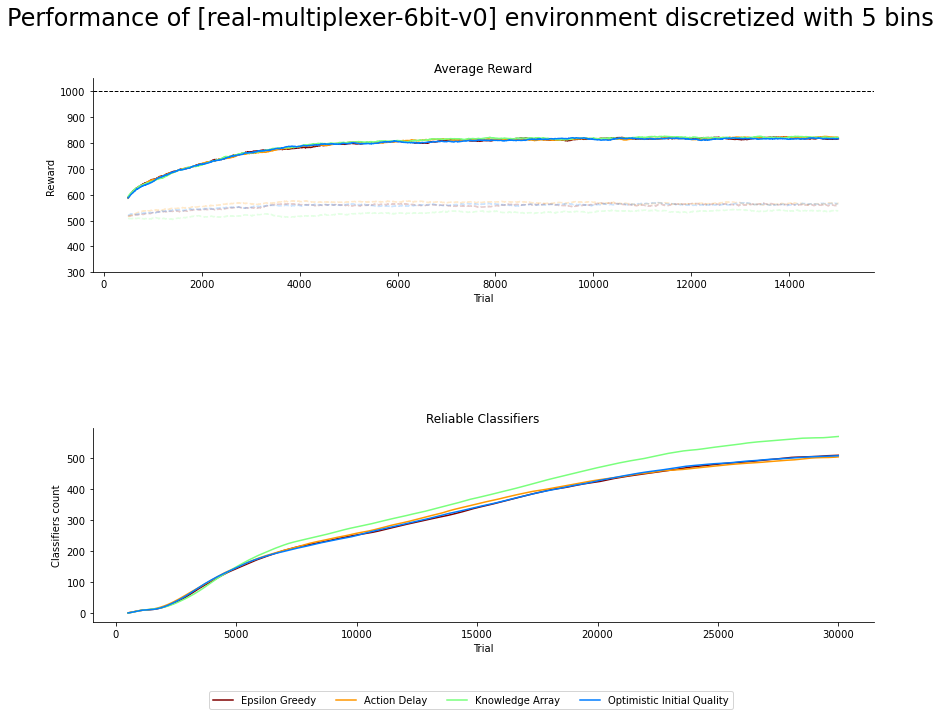
Fig. 4.1 6-bit rMPX discretized with 5 bins. Faded lines shows performance of explore mode, solid ones for exploit¶
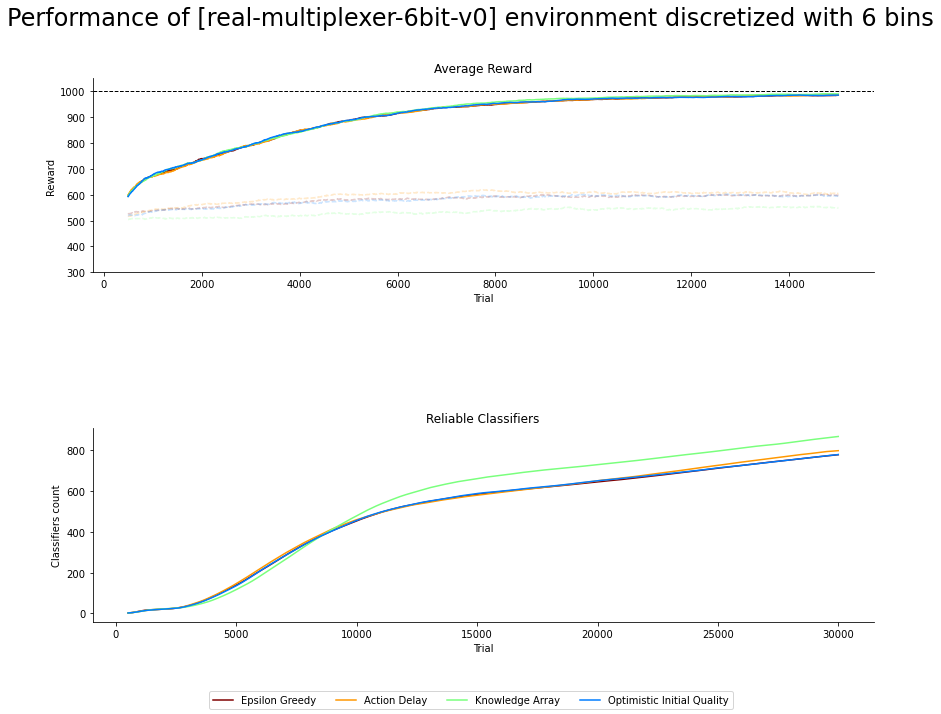
Fig. 4.2 6-bit rMPX discretized with 6 bins. Faded lines shows performance of explore mode, solid ones for exploit¶
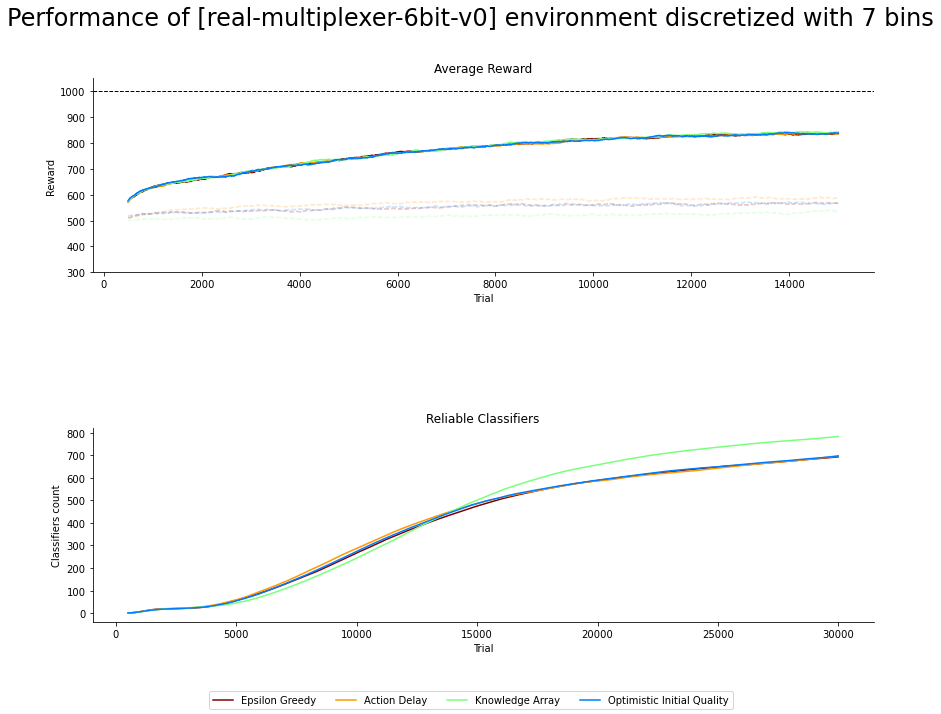
Fig. 4.3 6-bit rMPX discretized with 7 bins. Faded lines shows performance of explore mode, solid ones for exploit¶
Statistical verification¶
To statistically assess the population size, the posterior data distribution was modelled using 50 metric values collected in the last trial and then sampled with 100,000 draws. For the obtained reward, the average value from the last 100 exploit trials is considered a representative state of algorithm performance.
def train_bayes_model(dfs, query_condition, field):
data_arr = pd.concat(dfs).query(query_condition)[field].to_numpy()
bayes_model = bayes_estimate(data_arr)
return bayes_model['mu'], bayes_model['std']
def build_models(dfs: Dict, field: str, query_condition: str):
results = {}
for bins, dfs in dfs.items():
posteriors = [train_bayes_model(df, query_condition, field) for df in dfs]
results[bins] = posteriors
return results
def print_bayes_table(data):
table_data = [[f'{bins} bins'] + values for bins, values in data.items()]
table = tabulate(table_data,
headers=['', 'Epsilon Greedy', 'Action Delay', 'Knowledge Array', 'Optimistic Initial Quality'],
tablefmt="html", stralign='right', floatfmt=".2f")
return HTML(table)
print_row = lambda r: f'{round(r[0].mean(), 2)} ± {round(r[0].std(), 2)}'
experiments_data = {}
for bins, run_output in zip(
[bins_v1, bins_v2, bins_v3],
[rmpx_bins_v1(), rmpx_bins_v2(), rmpx_bins_v3()]):
experiments_data[bins] = extract(run_output)
# Average reward
def get_average_reward(dfs: [pd.DataFrame], last_n_runs: int = 100):
return pd.concat(dfs).query('phase == "explore"').groupby('trial').mean().iloc[-last_n_runs:]['reward'].mean()
average_rewards_data = {}
for bins, dfs in experiments_data.items():
average_rewards_data[bins] = list(map(get_average_reward, dfs))
# Reliable classifiers
@get_from_cache_or_run(cache_path=f'{cache_dir}/rmpx/bayes/reliable.dill')
def build_reliable_models(dfs: Dict):
return build_models(dfs, field='reliable', query_condition=f'trial == {rmpx_trials}')
reliable_data = build_reliable_models(experiments_data)
reliable_table_data = {}
for bins, models in reliable_data.items():
reliable_table_data[bins] = list(map(print_row, models))
# Add glue objects
glue('rmpx_average_reward', print_bayes_table(average_rewards_data), display=False)
glue('rmpx_bayes_reliable_classifies', print_bayes_table(reliable_table_data), display=False)
Epsilon Greedy Action Delay Knowledge Array Optimistic Initial Quality 5 bins 819.40 818.20 824.80 815.60 6 bins 985.40 986.20 987.40 984.80 7 bins 839.40 832.00 848.60 835.00
Epsilon Greedy Action Delay Knowledge Array Optimistic Initial Quality 5 bins 509.18 ± 3.67 505.28 ± 3.92 570.16 ± 4.08 508.31 ± 3.39 6 bins 781.81 ± 4.09 801.03 ± 4.03 872.07 ± 3.83 783.06 ± 3.89 7 bins 695.18 ± 3.72 698.2 ± 2.86 785.8 ± 3.22 698.58 ± 3.03
Observations¶
Despite the large size of the problem’s search space, the investigated biased exploration strategies have no impact on the average obtained reward. None of the methods can be distinguished by introducing peculiar rules into the population, imprinting on the performance. However, the differences between discretization resolution are depicted. The ACS2 agent selects valid action when six bins are used to divide the perception input range most of the time. The exploit performance is significantly worse for the other odd values but still better than random guessing.
The rate of reliable classifier acquisition begins equally for all the strategies and resolutions. After a few thousand trials, the KA method tends to drive the exploration process into the unknown regions of the space, therefore forming more and better novel rules. The performance of other approaches of EG, AD and OIQ is not distinguishable.
Software packages used
import session_info
session_info.show()
Click to view session information
----- gym 0.21.0 lcs NA matplotlib 3.5.1 myst_nb 0.13.1 pandas 1.4.0 session_info 1.0.0 src (embedded book's utils module) tabulate 0.8.9 -----
Click to view modules imported as dependencies
PIL 8.4.0 arviz 0.11.2 asttokens NA attr 21.4.0 babel 2.9.1 backcall 0.2.0 beta_ufunc NA binom_ufunc NA bitstring 3.1.7 brotli NA cachetools 5.0.0 certifi 2021.10.08 cffi 1.15.0 cftime 1.5.2 charset_normalizer 2.0.10 click 7.1.2 cloudpickle 2.0.0 colorama 0.4.4 colorful 0.5.4 colorful_orig 0.5.4 cryptography 36.0.1 cycler 0.10.0 cython_runtime NA databricks_cli NA dateutil 2.8.2 debugpy 1.5.1 decorator 5.1.1 defusedxml 0.7.1 dill 0.3.4 docutils 0.16 entrypoints 0.3 executing 0.8.2 fastprogress 0.2.7 filelock 3.4.2 google NA greenlet 1.1.2 grpc 1.43.0 gym_multiplexer NA hiredis 2.0.0 idna 3.3 imagesize NA importlib_metadata NA ipykernel 6.7.0 ipython_genutils 0.2.0 ipywidgets 7.6.5 jedi 0.18.1 jinja2 3.0.3 jsonschema 3.2.0 jupyter_cache 0.4.3 jupyter_sphinx 0.3.2 jupyterlab_pygments 0.1.2 kiwisolver 1.3.2 linkify_it 1.0.3 markdown_it 1.1.0 markupsafe 2.0.1 matplotlib_inline NA mdit_py_plugins 0.2.8 mistune 0.8.4 mlflow 1.23.1 mpl_toolkits NA msgpack 1.0.3 myst_parser 0.15.2 nbclient 0.5.10 nbconvert 6.4.1 nbformat 5.1.3 nbinom_ufunc NA netCDF4 1.5.8 numpy 1.22.1 packaging 21.3 pandocfilters NA parso 0.8.3 pexpect 4.8.0 pickleshare 0.7.5 pkg_resources NA prompt_toolkit 3.0.26 psutil 5.9.0 ptyprocess 0.7.0 pure_eval 0.2.2 pvectorc NA pydev_ipython NA pydevconsole NA pydevd 2.6.0 pydevd_concurrency_analyser NA pydevd_file_utils NA pydevd_plugins NA pydevd_tracing NA pygments 2.11.2 pylab NA pymc3 3.11.4 pyparsing 3.0.7 pyrsistent NA pytz 2021.3 ray 1.9.2 redis 4.1.2 requests 2.27.1 scipy 1.7.3 semver 2.13.0 setproctitle 1.2.2 setuptools 60.5.0 six 1.16.0 socks 1.7.1 sphinx 4.4.0 sphinxcontrib NA sqlalchemy 1.4.31 stack_data 0.1.4 testpath 0.5.0 theano 1.1.2 tornado 6.1 tqdm 4.62.3 traitlets 5.1.1 typing_extensions NA uc_micro 1.0.1 unicodedata2 NA urllib3 1.26.8 wcwidth 0.2.5 xarray 0.21.0 yaml 6.0 zipp NA zmq 22.3.0
----- IPython 8.0.1 jupyter_client 7.1.2 jupyter_core 4.9.1 notebook 6.4.8 ----- Python 3.9.10 | packaged by conda-forge | (main, Feb 1 2022, 21:24:11) [GCC 9.4.0] Linux-5.13.0-30-generic-x86_64-with-glibc2.31 ----- Session information updated at 2022-02-24 11:15