Experiment 2 - Multi-steps problems performance
Contents
import pathlib
from typing import List, Dict
import gym
import matplotlib.pyplot as plt
import matplotlib.ticker as mtick
import pandas as pd
from IPython.display import HTML
from lcs.agents.acs2 import Configuration, ACS2
from lcs.metrics import population_metrics
from lcs.strategies.action_selection import EpsilonGreedy, ActionDelay, KnowledgeArray
from myst_nb import glue
from tabulate import tabulate
from src.bayes_estimation import bayes_estimate
from src.commons import NUM_EXPERIMENTS
from src.decorators import repeat, get_from_cache_or_run
from src.metrics import parse_experiments_results, corridor_transition_knowledge, grid_transition_knowledge
from src.utils import build_plots_dir_path, build_cache_dir_path
from src.visualization import biased_exploration_colors, PLOT_DPI
COLORS = biased_exploration_colors()
plt.ioff() # turn off interactive plotting
root_dir = pathlib.Path().cwd().parent.parent.parent
cwd_dir = pathlib.Path().cwd()
plot_dir = build_plots_dir_path(root_dir) / cwd_dir.name
cache_dir = build_cache_dir_path(root_dir) / cwd_dir.name
def run_experiment(env_provider, explore_trials, exploit_trials, **conf):
env = env_provider()
env.reset()
cfg = Configuration(**conf)
explorer = ACS2(cfg)
metrics_explore = explorer.explore(env, explore_trials)
exploiter = ACS2(cfg, explorer.population)
metrics_exploit = explorer.exploit(env, exploit_trials)
# Parse results into DataFrame
metrics_df = parse_experiments_results(metrics_explore, metrics_exploit, cfg.metrics_trial_frequency)
return metrics_df
def extract(combined_list):
env1_dfs = [result[0] for result in combined_list]
env2_dfs = [result[1] for result in combined_list]
env3_dfs = [result[2] for result in combined_list]
return env1_dfs, env2_dfs, env3_dfs
def average_experiment_runs(runs_dfs: List[pd.DataFrame]) -> pd.DataFrame:
return pd.concat(runs_dfs).groupby(['trial', 'phase']).mean().reset_index(level='phase')
def plot(epsilon_greedy_df, action_delay_df, knowledge_array_df, op_initial_df,
env_name,
num_explore_trials,
first_knowledge_trials,
first_population_trials,
population_ylim,
text_box_loc,
plot_filename=None):
fig = plt.figure(figsize=(14, 8))
# Layout
gs = fig.add_gridspec(2, 2, wspace=.25, hspace=.4)
ax1 = fig.add_subplot(gs[0, 0])
ax2 = fig.add_subplot(gs[0, 1])
ax3 = fig.add_subplot(gs[1, :])
# Global title
fig.suptitle(f'Performance of [{env_name}] environment', fontsize=24)
# Knowledge
epsilon_greedy_df['knowledge'][:first_knowledge_trials].plot(label='Epsilon Greedy', c=COLORS['eg'], ax=ax1)
action_delay_df['knowledge'][:first_knowledge_trials].plot(label='Action Delay', c=COLORS['ad'], ax=ax1)
knowledge_array_df['knowledge'][:first_knowledge_trials].plot(label='Knowledge Array', c=COLORS['ka'], ax=ax1)
op_initial_df['knowledge'][:first_knowledge_trials].plot(label='Optimistic Initial Quality', c=COLORS['oiq'], ax=ax1)
ax1.spines['top'].set_visible(False)
ax1.spines['right'].set_visible(False)
ax1.set_title('Knowledge')
ax1.set_xlabel('Trial')
ax1.set_ylabel('Knowledge')
ax1.axhline(y=100, color='black', linewidth=1, linestyle="--")
ax1.yaxis.set_major_formatter(mtick.PercentFormatter())
# Population
epsilon_greedy_df['population'][:first_population_trials].plot(label='Epsilon Greedy', c=COLORS['eg'], ax=ax2)
action_delay_df['population'][:first_population_trials].plot(label='Action Delay', c=COLORS['ad'], ax=ax2)
knowledge_array_df['population'][:first_population_trials].plot(label='Knowledge Array', c=COLORS['ka'], ax=ax2)
op_initial_df['population'][:first_population_trials].plot(label='Optimistic Initial Quality', c=COLORS['oiq'], ax=ax2)
ax2.spines['top'].set_visible(False)
ax2.spines['right'].set_visible(False)
ax2.set_xlabel('Trial')
ax2.set_ylabel('Classifiers')
ax2.set_title('Classifiers Population')
ax2.set_ylim(population_ylim)
ax2.xaxis.set_major_formatter(mtick.FormatStrFormatter('%.0f'))
ax2.yaxis.set_major_formatter(mtick.FormatStrFormatter('%.0f'))
# Steps in trial
window = 3 # window for moving average
epsilon_greedy_df['steps_in_trial'].rolling(window=window).mean().plot(label='Epsilon Greedy', c=COLORS['eg'], ax=ax3)
action_delay_df['steps_in_trial'].rolling(window=window).mean().plot(label='Action Delay', c=COLORS['ad'], ax=ax3)
knowledge_array_df['steps_in_trial'].rolling(window=window).mean().plot(label='Knowledge Array', c=COLORS['ka'], ax=ax3)
op_initial_df['steps_in_trial'].rolling(window=window).mean().plot(label='Optimistic Initial Quality', c=COLORS['oiq'], ax=ax3)
ax3.spines['top'].set_visible(False)
ax3.spines['right'].set_visible(False)
ax3.set_xlabel('Trial')
ax3.set_ylabel('Steps')
ax3.set_title('Steps in trial')
ax3.axvline(x=num_explore_trials, color='black', linewidth=1, linestyle="--")
ax3.text(**text_box_loc, s=f'Moving average of {window} samples', style='italic',
bbox={'facecolor': 'red', 'alpha': 0.2, 'pad': 10})
# Create legend
handles, labels = ax3.get_legend_handles_labels()
fig.legend(handles, labels, loc='lower center', ncol=4)
if plot_filename:
fig.savefig(plot_filename, dpi=PLOT_DPI)
return fig
USE_RAY = True
explore_trials, exploit_trials = 60, 20
glue('41_e2_explore_trials', explore_trials, display=False)
glue('41_e2_exploit_trials', exploit_trials, display=False)
Experiment 2 - Multi-steps problems performance¶
Both Corridor and Grid multiple-step environments were used for verifying the biased exploration strategies. In each case the ACS2 agent starts by performing 60 explore trials with selected strategy, followed by 20 where the evolved population is validated.
The following metrics are considered:
knowledge - depicting the process of building an internal model,
population size - demonstrate the total number of classifiers,
steps in a trial - both in explore and exploit phase.
Figures 4.4 and 4.5 present the metric evolution for the basic versions of Corridor and Grid problems, containing 20 and 400 distinct states respectively, but the overall metrics look similar for larger instances. Additionally, for the Corridor, the cross-over capability of the agent was switched off because of the unit length of the perception vector \(\sigma\).
To amplify the agent’s motivation for exploring possible options, each problem was additionally increased to the sizes of \(n=40\) and \(n=100\). Last trial statistical inferences were collected in all cases to estimate overall performance.
Results¶
Corridor ACS2 parameters
\(\beta=0.2\), \(\gamma = 0.95\), \(\theta_r = 0.9\), \(\theta_i=0.1\), \(\epsilon = 0.8\) \(\theta_{GA} = 50\), \(\theta_{AS}=20\), \(\theta_{exp}=50\), \(m_u=0.03\), \(\chi=0\)
import gym_corridor # noqa: F401
from src.observation_wrappers import CorridorObservationWrapper
def corridor20_env_provider():
import gym_corridor # noqa: F401
return CorridorObservationWrapper(gym.make(f'corridor-20-v0'))
def corridor40_env_provider():
import gym_corridor # noqa: F401
return CorridorObservationWrapper(gym.make(f'corridor-40-v0'))
def corridor100_env_provider():
import gym_corridor # noqa: F401
return CorridorObservationWrapper(gym.make(f'corridor-100-v0'))
# Function for calculating relevant metrics
def corridor_metrics(agent, env):
pop = agent.population
metrics = {
'knowledge': corridor_transition_knowledge(pop, env)
}
metrics.update(population_metrics(pop, env))
return metrics
corridor_base_params = {
"classifier_length": 1,
"number_of_possible_actions": 2,
"epsilon": 0.8,
"beta": 0.2,
"gamma": 0.95,
"initial_q": 0.5,
"theta_exp": 50,
"theta_ga": 50,
"do_ga": True,
"mu": 0.03,
"u_max": 1,
"metrics_trial_frequency": 1,
"user_metrics_collector_fcn": corridor_metrics
}
# Start experiments
@get_from_cache_or_run(cache_path=f'{cache_dir}/corridor/epsilon_greedy.dill')
@repeat(num_times=NUM_EXPERIMENTS, use_ray=USE_RAY)
def corridor_epsilon_greedy():
corridor20 = run_experiment(corridor20_env_provider, explore_trials, exploit_trials, **(corridor_base_params | {'action_selector': EpsilonGreedy}))
corridor40 = run_experiment(corridor40_env_provider, explore_trials, exploit_trials, **(corridor_base_params | {'action_selector': EpsilonGreedy}))
corridor100 = run_experiment(corridor100_env_provider, explore_trials, exploit_trials, **(corridor_base_params | {'action_selector': EpsilonGreedy}))
return corridor20, corridor40, corridor100
@get_from_cache_or_run(cache_path=f'{cache_dir}/corridor/action_delay.dill')
@repeat(num_times=NUM_EXPERIMENTS, use_ray=USE_RAY)
def corridor_action_delay():
corridor20 = run_experiment(corridor20_env_provider, explore_trials, exploit_trials, **(corridor_base_params | {'action_selector': ActionDelay, 'biased_exploration_prob': 0.5}))
corridor40 = run_experiment(corridor40_env_provider, explore_trials, exploit_trials, **(corridor_base_params | {'action_selector': ActionDelay, 'biased_exploration_prob': 0.5}))
corridor100 = run_experiment(corridor100_env_provider, explore_trials, exploit_trials, **(corridor_base_params | {'action_selector': ActionDelay, 'biased_exploration_prob': 0.5}))
return corridor20, corridor40, corridor100
@get_from_cache_or_run(cache_path=f'{cache_dir}/corridor/knowledge_array.dill')
@repeat(num_times=NUM_EXPERIMENTS, use_ray=USE_RAY)
def corridor_knowledge_array():
corridor20 = run_experiment(corridor20_env_provider, explore_trials, exploit_trials, **(corridor_base_params | {'action_selector': KnowledgeArray, 'biased_exploration_prob': 0.5}))
corridor40 = run_experiment(corridor40_env_provider, explore_trials, exploit_trials, **(corridor_base_params | {'action_selector': KnowledgeArray, 'biased_exploration_prob': 0.5}))
corridor100 = run_experiment(corridor100_env_provider, explore_trials, exploit_trials, **(corridor_base_params | {'action_selector': KnowledgeArray, 'biased_exploration_prob': 0.5}))
return corridor20, corridor40, corridor100
@get_from_cache_or_run(cache_path=f'{cache_dir}/corridor/oiq.dill')
@repeat(num_times=NUM_EXPERIMENTS, use_ray=USE_RAY)
def corridor_oiq():
corridor20 = run_experiment(corridor20_env_provider, explore_trials, exploit_trials, **(corridor_base_params | {'action_selector': EpsilonGreedy, 'biased_exploration_prob': 0.8}))
corridor40 = run_experiment(corridor40_env_provider, explore_trials, exploit_trials, **(corridor_base_params | {'action_selector': EpsilonGreedy, 'biased_exploration_prob': 0.8}))
corridor100 = run_experiment(corridor100_env_provider, explore_trials, exploit_trials, **(corridor_base_params | {'action_selector': EpsilonGreedy, 'biased_exploration_prob': 0.8}))
return corridor20, corridor40, corridor100
Grid ACS2 parameters
\(\beta=0.2\), \(\gamma = 0.95\), \(\theta_r = 0.9\), \(\theta_i=0.1\), \(\epsilon = 0.8\) \(\theta_{GA} = 50\), \(\theta_{AS}=20\), \(\theta_{exp}=50\), \(m_u=0.03\), \(u_{max}=1\), \(\chi=0.8\)
# Function for calculating relevant metrics
def grid_metrics(agent, env):
pop = agent.population
metrics = {
'knowledge': grid_transition_knowledge(pop, env)
}
metrics.update(population_metrics(pop, env))
return metrics
def grid20_env_provider():
import gym_grid # noqa: F401
return gym.make(f'grid-20-v0')
def grid40_env_provider():
import gym_grid # noqa: F401
return gym.make(f'grid-40-v0')
def grid100_env_provider():
import gym_grid # noqa: F401
return gym.make(f'grid-100-v0')
grid_base_params = {
"classifier_length": 2,
"number_of_possible_actions": 4,
"epsilon": 0.8,
"beta": 0.2,
"gamma": 0.95,
"initial_q": 0.5,
"theta_exp": 50,
"theta_ga": 50,
"do_ga": True,
"mu": 0.03,
"u_max": 1,
"metrics_trial_frequency": 1,
"user_metrics_collector_fcn": grid_metrics
}
# Start experiments
@get_from_cache_or_run(cache_path=f'{cache_dir}/grid/epsilon_greedy.dill')
@repeat(num_times=NUM_EXPERIMENTS, use_ray=USE_RAY)
def grid_epsilon_greedy():
grid20 = run_experiment(grid20_env_provider, explore_trials, exploit_trials, **(grid_base_params | {'action_selector': EpsilonGreedy}))
grid40 = run_experiment(grid40_env_provider, explore_trials, exploit_trials, **(grid_base_params | {'action_selector': EpsilonGreedy}))
grid100 = run_experiment(grid100_env_provider, explore_trials, exploit_trials, **(grid_base_params | {'action_selector': EpsilonGreedy}))
return grid20, grid40, grid100
@get_from_cache_or_run(cache_path=f'{cache_dir}/grid/action_delay.dill')
@repeat(num_times=NUM_EXPERIMENTS, use_ray=USE_RAY)
def grid_action_delay():
grid20 = run_experiment(grid20_env_provider, explore_trials, exploit_trials, **(grid_base_params | {'action_selector': ActionDelay, 'biased_exploration_prob': 0.5}))
grid40 = run_experiment(grid40_env_provider, explore_trials, exploit_trials, **(grid_base_params | {'action_selector': ActionDelay, 'biased_exploration_prob': 0.5}))
grid100 = run_experiment(grid100_env_provider, explore_trials, exploit_trials, **(grid_base_params | {'action_selector': ActionDelay, 'biased_exploration_prob': 0.5}))
return grid20, grid40, grid100
@get_from_cache_or_run(cache_path=f'{cache_dir}/grid/knowledge_array.dill')
@repeat(num_times=NUM_EXPERIMENTS, use_ray=USE_RAY)
def grid_knowledge_array():
grid20 = run_experiment(grid20_env_provider, explore_trials, exploit_trials, **(grid_base_params | {'action_selector': KnowledgeArray, 'biased_exploration_prob': 0.5}))
grid40 = run_experiment(grid40_env_provider, explore_trials, exploit_trials, **(grid_base_params | {'action_selector': KnowledgeArray, 'biased_exploration_prob': 0.5}))
grid100 = run_experiment(grid100_env_provider, explore_trials, exploit_trials, **(grid_base_params | {'action_selector': KnowledgeArray, 'biased_exploration_prob': 0.5}))
return grid20, grid40, grid100
@get_from_cache_or_run(cache_path=f'{cache_dir}/grid/oiq.dill')
@repeat(num_times=NUM_EXPERIMENTS, use_ray=USE_RAY)
def grid_oiq():
grid_20 = run_experiment(grid20_env_provider, explore_trials, exploit_trials, **(grid_base_params | {'action_selector': EpsilonGreedy, 'biased_exploration_prob': 0.8}))
grid_40 = run_experiment(grid40_env_provider, explore_trials, exploit_trials, **(grid_base_params | {'action_selector': EpsilonGreedy, 'biased_exploration_prob': 0.8}))
grid_100 = run_experiment(grid100_env_provider, explore_trials, exploit_trials, **(grid_base_params | {'action_selector': EpsilonGreedy, 'biased_exploration_prob': 0.8}))
return grid_20, grid_40, grid_100
# Execute calculations
corridor20_eg_dfs, corridor40_eg_dfs, corridor100_eg_dfs = extract(corridor_epsilon_greedy())
corridor20_ad_dfs, corridor40_ad_dfs, corridor100_ad_dfs = extract(corridor_action_delay())
corridor20_ka_dfs, corridor40_ka_dfs, corridor100_ka_dfs = extract(corridor_knowledge_array())
corridor20_oiq_dfs, corridor40_oiq_dfs, corridor100_oiq_dfs = extract(corridor_oiq())
grid20_eg_dfs, grid40_eg_dfs, grid100_eg_dfs = extract(grid_epsilon_greedy())
grid20_ad_dfs, grid40_ad_dfs, grid100_ad_dfs = extract(grid_action_delay())
grid20_ka_dfs, grid40_ka_dfs, grid100_ka_dfs = extract(grid_knowledge_array())
grid20_oiq_dfs, grid40_oiq_dfs, grid100_oiq_dfs = extract(grid_oiq())
# Plot results
glue('41-e2-corridor-fig', plot(
average_experiment_runs(corridor20_eg_dfs),
average_experiment_runs(corridor20_ad_dfs),
average_experiment_runs(corridor20_ka_dfs),
average_experiment_runs(corridor20_oiq_dfs),
env_name='Corridor-20',
num_explore_trials=explore_trials,
first_knowledge_trials=30,
first_population_trials=20,
population_ylim=(17, 40),
text_box_loc={"x": 63, "y": 120},
plot_filename=f'{plot_dir}/corridor-performance.png'
), display=False)
glue('41-e2-grid-fig', plot(
average_experiment_runs(grid20_eg_dfs),
average_experiment_runs(grid20_ad_dfs),
average_experiment_runs(grid20_ka_dfs),
average_experiment_runs(grid20_oiq_dfs),
env_name='Grid-20',
num_explore_trials=explore_trials,
first_knowledge_trials=10,
first_population_trials=30,
population_ylim=(70, 105),
text_box_loc={"x": 63, "y": 1000},
plot_filename=f'{plot_dir}/grid-performance.png'
), display=False)
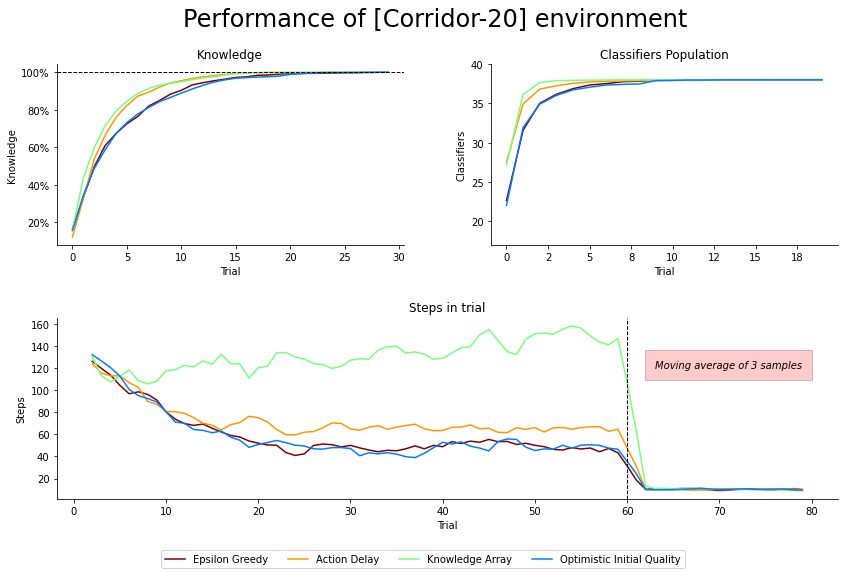
Fig. 4.4 Performance of Corridor-20 environment. 60 exploration and 20 exploitation trials averaged over 50 runs. Steps in a trial was plotted with a moving average of 3 last steps for clarity. No explicit discretizer was needed. The maximum number of steps in a trial is 200. The dotted vertical line indicates the execution of explore and exploit phases.¶
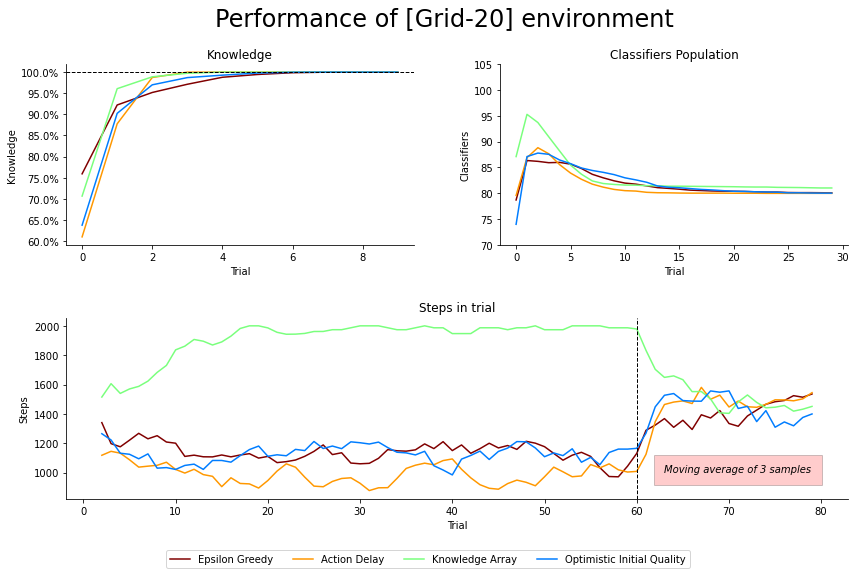
Fig. 4.5 Performance of Grid-20 environment. 60 exploration and 20 exploitation trials averaged over 50 runs. Steps in a trial was plotted with a moving average of 3 last steps for clarity. No explicit discretizer was needed. The maximum number of steps in a trial is 2000. The dotted vertical line indicates the execution of explore and exploit phases.¶
Statistical verification¶
To statistically assess the population size, the posterior data distribution was modelled using 50 metric values collected in the last trial and then sampled with 100,000 draws. For the obtained reward, the average value from exploit trials is considered a representative state of algorithm performance.
def build_models(dfs: Dict[str, pd.DataFrame], field: str, query_condition: str):
results = {}
for name, df in dfs.items():
data_arr = df.query(query_condition)[field].to_numpy()
bayes_model = bayes_estimate(data_arr)
results[name] = (bayes_model['mu'], bayes_model['std'])
return results
def get_average_reward(dfs: Dict[str, pd.DataFrame]):
results = {}
for name, df in dfs.items():
results[name] = df.query('phase == "exploit"')['reward'].mean()
return results
experiments_data = {
'corridor20_eg': pd.concat(corridor20_eg_dfs),
'corridor40_eg': pd.concat(corridor40_eg_dfs),
'corridor100_eg': pd.concat(corridor100_eg_dfs),
'corridor20_ad': pd.concat(corridor20_ad_dfs),
'corridor40_ad': pd.concat(corridor40_ad_dfs),
'corridor100_ad': pd.concat(corridor100_ad_dfs),
'corridor20_ka': pd.concat(corridor20_ka_dfs),
'corridor40_ka': pd.concat(corridor40_ka_dfs),
'corridor100_ka': pd.concat(corridor100_ka_dfs),
'corridor20_oiq': pd.concat(corridor20_oiq_dfs),
'corridor40_oiq': pd.concat(corridor40_oiq_dfs),
'corridor100_oiq': pd.concat(corridor100_oiq_dfs),
'grid20_eg': pd.concat(grid20_eg_dfs),
'grid40_eg': pd.concat(grid40_eg_dfs),
'grid100_eg': pd.concat(grid100_eg_dfs),
'grid20_ad': pd.concat(grid20_ad_dfs),
'grid40_ad': pd.concat(grid40_ad_dfs),
'grid100_ad': pd.concat(grid100_ad_dfs),
'grid20_ka': pd.concat(grid20_ka_dfs),
'grid40_ka': pd.concat(grid40_ka_dfs),
'grid100_ka': pd.concat(grid100_ka_dfs),
'grid20_oiq': pd.concat(grid20_oiq_dfs),
'grid40_oiq': pd.concat(grid40_oiq_dfs),
'grid100_oiq': pd.concat(grid100_oiq_dfs)
}
@get_from_cache_or_run(cache_path=f'{cache_dir}/bayes/population.dill')
def build_population_models(dfs: Dict[str, pd.DataFrame]):
return build_models(dfs, field='population', query_condition=f'trial == {explore_trials - 1}')
@get_from_cache_or_run(cache_path=f'{cache_dir}/bayes/reliable.dill')
def build_reliable_models(dfs: Dict[str, pd.DataFrame]):
return build_models(dfs, field='reliable', query_condition=f'trial == {explore_trials - 1}')
@get_from_cache_or_run(cache_path=f'{cache_dir}/bayes/knowledge.dill')
def build_knowledge_models(dfs: Dict[str, pd.DataFrame]):
return build_models(dfs, field='knowledge', query_condition=f'trial == {explore_trials - 1}')
@get_from_cache_or_run(cache_path=f'{cache_dir}/bayes/perf_time.dill')
def build_perf_time_models(dfs: Dict[str, pd.DataFrame]):
return build_models(dfs, field='perf_time', query_condition=f'phase == "explore"')
population_models = build_population_models(experiments_data)
reliable_models = build_reliable_models(experiments_data)
knowledge_models = build_knowledge_models(experiments_data)
perf_time_models = build_perf_time_models(experiments_data)
avg_rewards = get_average_reward(experiments_data)
def print_bayes_table(name_prefix, population_models, reliable_models, knowledge_models, perf_time_models, avg_rewards):
print_row = lambda r: f'{round(r[0].mean(), 2)} ± {round(r[0].std(), 2)}'
key_names = [name for name in experiments_data.keys() if name.startswith(name_prefix)]
bayes_table_data = [
['population of classifiers'] + [print_row(v) for name, v in population_models.items() if name in key_names],
['reliable classifiers'] + [print_row(v) for name, v in reliable_models.items() if name in key_names],
['knowledge'] + [print_row(v) for name, v in knowledge_models.items() if name in key_names],
['trial execution time'] + [print_row(v) for name, v in perf_time_models.items() if name in key_names],
['average exploit reward'] + [f'{round(v, 2)}' for name, v in avg_rewards.items() if name in key_names],
]
table = tabulate(bayes_table_data,
headers=['', 'Epsilon Greedy', 'Action Delay', 'Knowledge Array', 'Optimistic Initial Quality'],
tablefmt="html",
stralign='right')
return HTML(table)
# Add glue for rendering output in tabs
glue("corridor20", print_bayes_table('corridor20', population_models, reliable_models, knowledge_models, perf_time_models, avg_rewards), display=False)
glue("corridor40", print_bayes_table('corridor40', population_models, reliable_models, knowledge_models, perf_time_models, avg_rewards), display=False)
glue("corridor100", print_bayes_table('corridor100', population_models, reliable_models, knowledge_models, perf_time_models, avg_rewards), display=False)
glue("grid20", print_bayes_table('grid20', population_models, reliable_models, knowledge_models, perf_time_models, avg_rewards), display=False)
glue("grid40", print_bayes_table('grid40', population_models, reliable_models, knowledge_models, perf_time_models, avg_rewards), display=False)
glue("grid100", print_bayes_table('grid100', population_models, reliable_models, knowledge_models, perf_time_models, avg_rewards), display=False)
Corridor¶
Epsilon Greedy Action Delay Knowledge Array Optimistic Initial Quality population of classifiers 38.0 ± 0.0 38.0 ± 0.0 38.0 ± 0.0 38.0 ± 0.0 reliable classifiers 38.0 ± 0.0 38.0 ± 0.0 38.0 ± 0.0 38.0 ± 0.0 knowledge 100.0 ± 0.0 100.0 ± 0.0 100.0 ± 0.0 100.0 ± 0.0 trial execution time 0.02 ± 0.0 0.03 ± 0.0 0.05 ± 0.0 0.02 ± 0.0 average exploit reward 1000.0 1000.0 1000.0 1000.0
Epsilon Greedy Action Delay Knowledge Array Optimistic Initial Quality population of classifiers 78.0 ± 0.0 78.0 ± 0.0 78.0 ± 0.0 78.0 ± 0.0 reliable classifiers 78.0 ± 0.0 78.0 ± 0.0 78.0 ± 0.0 78.0 ± 0.0 knowledge 100.0 ± 0.0 100.0 ± 0.0 100.0 ± 0.0 100.0 ± 0.0 trial execution time 0.06 ± 0.0 0.07 ± 0.0 0.09 ± 0.0 0.06 ± 0.0 average exploit reward 949.0 998.0 1000.0 962.0
Epsilon Greedy Action Delay Knowledge Array Optimistic Initial Quality population of classifiers 198.0 ± 0.0 198.0 ± 0.0 198.0 ± 0.0 198.0 ± 0.0 reliable classifiers 195.25 ± 0.53 195.78 ± 0.38 196.0 ± 0.0 195.67 ± 0.39 knowledge 98.63 ± 0.27 98.88 ± 0.2 98.98 ± 0.0 98.83 ± 0.21 trial execution time 0.15 ± 0.0 0.16 ± 0.0 0.17 ± 0.0 0.16 ± 0.0 average exploit reward 228.0 222.0 329.0 217.0
Grid¶
Epsilon Greedy Action Delay Knowledge Array Optimistic Initial Quality population of classifiers 80.0 ± 0.0 80.0 ± 0.0 80.0 ± 0.0 80.0 ± 0.0 reliable classifiers 80.0 ± 0.0 80.0 ± 0.0 80.0 ± 0.0 80.0 ± 0.0 knowledge 100.0 ± 0.0 100.0 ± 0.0 100.0 ± 0.0 100.0 ± 0.0 trial execution time 0.73 ± 0.01 0.69 ± 0.01 1.32 ± 0.0 0.72 ± 0.01 average exploit reward 459.0 440.0 377.0 448.0
Epsilon Greedy Action Delay Knowledge Array Optimistic Initial Quality population of classifiers 160.0 ± 0.0 160.0 ± 0.0 161.67 ± 0.34 160.0 ± 0.0 reliable classifiers 160.0 ± 0.0 160.0 ± 0.0 161.24 ± 0.24 160.0 ± 0.0 knowledge 100.0 ± 0.0 100.0 ± 0.0 100.0 ± 0.0 100.0 ± 0.0 trial execution time 1.65 ± 0.02 1.63 ± 0.01 1.74 ± 0.01 1.67 ± 0.02 average exploit reward 197.0 191.0 141.0 216.0
Epsilon Greedy Action Delay Knowledge Array Optimistic Initial Quality population of classifiers 404.67 ± 0.54 401.98 ± 0.3 409.1 ± 0.87 403.7 ± 0.57 reliable classifiers 400.0 ± 0.0 400.0 ± 0.0 401.45 ± 0.25 400.0 ± 0.0 knowledge 100.0 ± 0.0 100.0 ± 0.0 100.0 ± 0.0 100.0 ± 0.0 trial execution time 3.24 ± 0.02 3.33 ± 0.02 3.35 ± 0.02 3.23 ± 0.02 average exploit reward 47.0 45.0 24.0 17.0
Observations¶
Corridor
Based on the Figure 4.4 all methods converge to optimal population size, and after switching to the exploitation mode, can utilize gained knowledge fully. Regardless of the exploration technique chosen, the agent can obtain complete knowledge of the environment in about 20 trials. AD and KA techniques seem to reach this point faster than the baseline EG and with OIQ modification.
The AD and KA methods accelerate the process of investigating the search-space resulting in earlier classifier creation.
Finally, the agent can fully exploit the environment after switching to “exploit” mode performing a minimal number of steps to reach the goal in each trial. Its also worth mentioning the constant effect of the KA method in explore phase, not taking the optimal actions most of the time, by continually updating the assumptions about all possibilities.
However, when the problem size increased twice (\(n=40\)), while all strategies obtained full knowledge of the environment, only the KA method managed to exploit it totally unerringly. This difference is highlighted more for \(n=100\), where only about a third of all exploit trials were successful by KA, and other strategies performed significantly worse.
Grid
Performance plot using Grid of size \(n=20\) in Figure 4.5 shows that regardless of exploration technique chosen, the agent is still able to obtain full knowledge of the environment (even faster than in Corridor) and converge with the number of optimal classifiers (KA method here also creates much more classifiers at the beginning of the experimentation).
Interestingly, the KA obtains the worst average reward despite having the largest amount of reliable classifiers for problems where \(n=20\) and \(n=40\).
Moreover, what is interesting is that the agent cannot exploit the environment even though it knows the exact consequences of each action (non-optimal number of steps in the exploitation phase). After investigation, it was found that most classifiers have a very similar \(cl.r\) value, representing the expected future reward. The agent in the current form is unable to differentiate between aliasing states, resulting in an inability to form an optimal policy. This finding emphasizes a need for a universal metric for quantifying the agent’s performance. The current definition of knowledge, modelling only encountered transitions, is inaccurate when the estimated reward is not distributed correctly amongst participating classifiers.
Software packages used
import session_info
session_info.show()
Click to view session information
----- gym 0.21.0 gym_corridor NA lcs NA matplotlib 3.5.1 myst_nb 0.13.1 pandas 1.4.0 session_info 1.0.0 src (embedded book's utils module) tabulate 0.8.9 -----
Click to view modules imported as dependencies
PIL 8.4.0 arviz 0.11.2 asttokens NA attr 21.4.0 babel 2.9.1 backcall 0.2.0 beta_ufunc NA binom_ufunc NA brotli NA cachetools 5.0.0 certifi 2021.10.08 cffi 1.15.0 cftime 1.5.2 charset_normalizer 2.0.10 click 7.1.2 cloudpickle 2.0.0 colorama 0.4.4 colorful 0.5.4 colorful_orig 0.5.4 cryptography 36.0.1 cycler 0.10.0 cython_runtime NA databricks_cli NA dateutil 2.8.2 debugpy 1.5.1 decorator 5.1.1 defusedxml 0.7.1 dill 0.3.4 docutils 0.16 entrypoints 0.3 executing 0.8.2 fastprogress 0.2.7 filelock 3.4.2 google NA greenlet 1.1.2 grpc 1.43.0 hiredis 2.0.0 idna 3.3 imagesize NA importlib_metadata NA ipykernel 6.7.0 ipython_genutils 0.2.0 ipywidgets 7.6.5 jedi 0.18.1 jinja2 3.0.3 jsonschema 3.2.0 jupyter_cache 0.4.3 jupyter_sphinx 0.3.2 jupyterlab_pygments 0.1.2 kiwisolver 1.3.2 linkify_it 1.0.3 markdown_it 1.1.0 markupsafe 2.0.1 matplotlib_inline NA mdit_py_plugins 0.2.8 mistune 0.8.4 mlflow 1.23.1 mpl_toolkits NA msgpack 1.0.3 myst_parser 0.15.2 nbclient 0.5.10 nbconvert 6.4.1 nbformat 5.1.3 nbinom_ufunc NA netCDF4 1.5.8 numpy 1.22.1 packaging 21.3 pandocfilters NA parso 0.8.3 pexpect 4.8.0 pickleshare 0.7.5 pkg_resources NA prompt_toolkit 3.0.26 psutil 5.9.0 ptyprocess 0.7.0 pure_eval 0.2.2 pvectorc NA pydev_ipython NA pydevconsole NA pydevd 2.6.0 pydevd_concurrency_analyser NA pydevd_file_utils NA pydevd_plugins NA pydevd_tracing NA pygments 2.11.2 pylab NA pymc3 3.11.4 pyparsing 3.0.7 pyrsistent NA pytz 2021.3 ray 1.9.2 redis 4.1.2 requests 2.27.1 scipy 1.7.3 semver 2.13.0 setproctitle 1.2.2 setuptools 60.5.0 six 1.16.0 socks 1.7.1 sphinx 4.4.0 sphinxcontrib NA sqlalchemy 1.4.31 stack_data 0.1.4 testpath 0.5.0 theano 1.1.2 tornado 6.1 tqdm 4.62.3 traitlets 5.1.1 typing_extensions NA uc_micro 1.0.1 unicodedata2 NA urllib3 1.26.8 wcwidth 0.2.5 xarray 0.21.0 yaml 6.0 zipp NA zmq 22.3.0
----- IPython 8.0.1 jupyter_client 7.1.2 jupyter_core 4.9.1 notebook 6.4.8 ----- Python 3.9.10 | packaged by conda-forge | (main, Feb 1 2022, 21:24:11) [GCC 9.4.0] Linux-5.13.0-30-generic-x86_64-with-glibc2.31 ----- Session information updated at 2022-02-24 12:57